

建模和机器学习常常会让人感觉像是难以探索和学习的课题,尤其是对那些不熟悉计算机科学和数学领域的人来说尤为如此。我很惊讶地从我的非理工科的朋友那里听到,他们在自己的项目中尝试使用基本的建模技术时感到不知所措,而且他们可能会陷入这个领域的语义中。这是一种耻辱,因为线性建模在许多情况下都是非常有用的,并且加上互联网上的所有开放源代码,实现自己的模型从未如此简单过。因此,下面是我用 Python 理解并实现基本线性回归模型的简单指南。
线性回归是一种数学建模的一种形式,通常用于评估因变量(如体重)和自变量(如身高)之间的关系。我们的大脑能够很自然地做到这一点,只是以一种不太精确的方式而已。如果我让你判定 189 厘米和 158 厘米的人哪个人体重更重,你可能会选择 189 厘米的人。当然,158 厘米的人也可能会更重,但我敢打赌,在你与人交往的经历中,你已经确定了人的身高与体重之间的某种关系。线性回归就是建立这种关系并从中提取意义的一种精确的数学方法。
线性回归的工作原理是通过创建一条最佳拟合线。最佳拟合线是最能捕捉 X 轴和 Y 轴之间关系的直线。例如,这种关系可以是,随着“X”的增加,“Y”也会随之增加:
随着 X 增加,Y 也随之增加。
或者,这种关系也可以是:随着“X”增加,“Y”也随之减少。
随着 X 增加,Y 也随之减少。
在上面的示例中,确定趋势的大致方向是很容易的。但是,根据数据,它可能会变得更加复杂。此外,这条线的精确细节可能很难手工计算。在许多情况下,得到直线的精确方程会非常有帮助,使我们能够理解这两个变量之间的关系,并根据另一个变量的值来推测另一个变量的值。
为了使线性回归有效发挥作用,你至少需要两个变量:一个你认为可能是因变量的变量,如 NBA 球员的体重(以公斤为单位),另一个你认为可能是影响该因变量的变量,比如 NBA 球员的身高(以厘米为单位)。
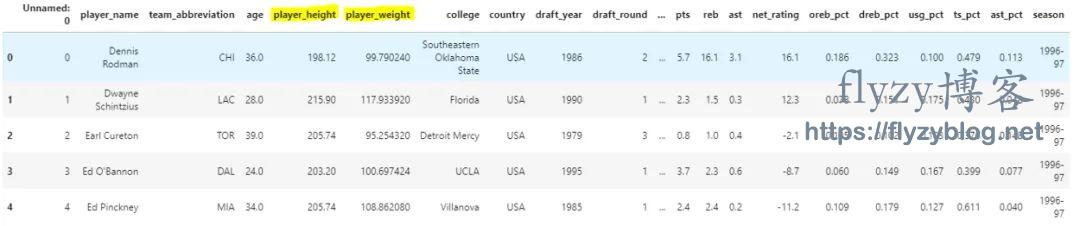
一个 Pandas 数据帧,包含与 NBA 球员有关的各种数据点,其中包括身高和体重
如果这两个变量都是连续的,那么线性回归的效果最好。我所说的连续是指两个值之间有一个连续性。有些人的体重可以是 68.49 公斤,或 68.95 公斤,或 68.72 公斤,或 68.82 公斤,等等。这不同于离散的或分类变量(例如电影分级或课堂上给出的分数)。还有其他技术可以处理这些类型的数据,但我们现在将重点放在线性回归。
身高和体重是连续变量素数之间建立线性关系的两个完美示例。如果你使用的是 Python,请确保这两个连续变量都是 浮点型 的,这将对后面的步骤有所帮助。
如果你有兴趣使用已经清理过的数据集进行尝试这一操作,你可以跟随我正在使用的 NBA 数据集(可以在 这里 找到)。
为了加载数据,我推荐使用 Python 的 Pandas 包:
import pandas as pd #Load the Pandas package
df = pd.read_csv("archive/all_seasons.csv") #Read the NBA file
df.head() #Display the NBA file's data
输出应该与上面所示的表类似。
现在,我们已经加载了数据,让我们来看看 NBA 球员的体重和身高之间的关系:
df.plot.scatter("player_height","player_weight", figsize=(15,10))
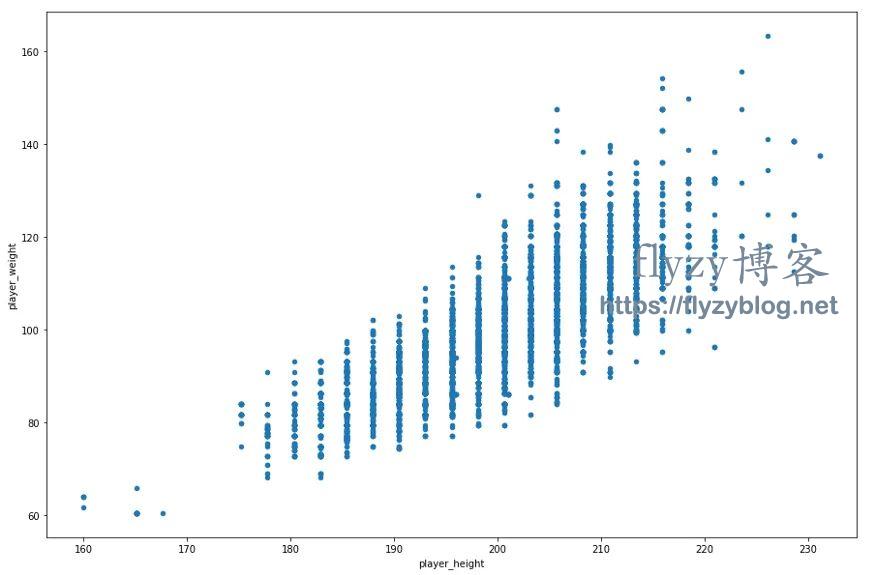
NBA 球员身高(X 轴)和体重(Y 轴)的散点图。
除了一些离群值外,我们已经可以看到,NBA 球员的身高和体重之间存在着直接的相关性。正如我们上面所揭示的,线性回归就像从图的左边到图的右边绘制出了一条最符合数据关系的直线。以我们的 NBA 球员为例,我们可以猜测,最佳拟合线应该是从 60 公斤左右的某处开始,然后向右上角移动。问题在于,我们人类远远不够精确,无法绘制出一条能够完美捕捉数据趋势的直线。取而代之的是,让我们使用一个工具。
Scikit-Learn,或称 SKLearn,是一个 Python 包,包含了各种机器学习工具,其中有一种用于以简单有效的方式构建线性回归模型的工具。要使用 SKLearn,我们需要从 Pandas 数据帧中分离出两个变量:
from sklearn import linear_model
#By calling to_numpy() we convert the series into a numpy array
#We then reshape the numpy array into a format parsable for sklearn
X = df["player_height"].to_numpy().reshape(-1, 1)
y = df["player_weight"].to_numpy().reshape(-1, 1)
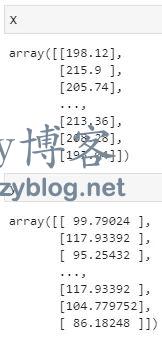
我们的数据现在是 NumPy 数组格式。
正如你所见,“X”数组包含了所有的身高,“Y”数组包含了所有的体重。现在,我们可以对模型进行拟合了。在这种情况下,对模型进行拟合意味着我们正将数据呈现给函数,并允许 SKLearn 找到最能捕捉“X”和“Y”之间关系的直线。
#First we call the linear regression function from SKLearn linear_model
#Then using this object we fit the data to a linear model.
lm = linear_model.LinearRegression()
model = lm.fit(X,y)
现在模型已经拟合好,让我们看看它产生了什么样的结果。
在我们的模型完成拟合之后,是时候看看它从我们提供的数据中建立了什么。首先,让我们看看它为数据评估的参数:
print(model.coef_) #prints the slope of the line
[1]: [[1.13557995]]
print(model.intercept_) #prints the intercept of the line
[2]: [-127.40114263]
对于熟悉数学的人来说,你可能还记得直线斜率的公式是 y = mx + b。在这种情况下,“b”是截距,可以认为是直线与 Y 轴相交的位置,而“m”是直线的斜率。因此,对于我们拟合的线性回归模型,方程式大致为 y = 1.13x – 127.4。这意味着,“x”每增加一个数字,“y”就增加 1.13,或者更确切地说,球员身高每增加 1 厘米,球员的体重就应该增加 1.13 公斤。从视觉上看,如果我们在 NBA 球员身高和体重的散点图上绘制出这条直线,我们就会得到:
import numpy as np #numpy can be used for creating a lsit of numbers
X = np.arange(150,250) # create a list of example values
#plot
df.plot.scatter("player_height","player_weight", figsize=(15,10)).plot(X, model.predict(X.reshape(-1,1)),color='k')
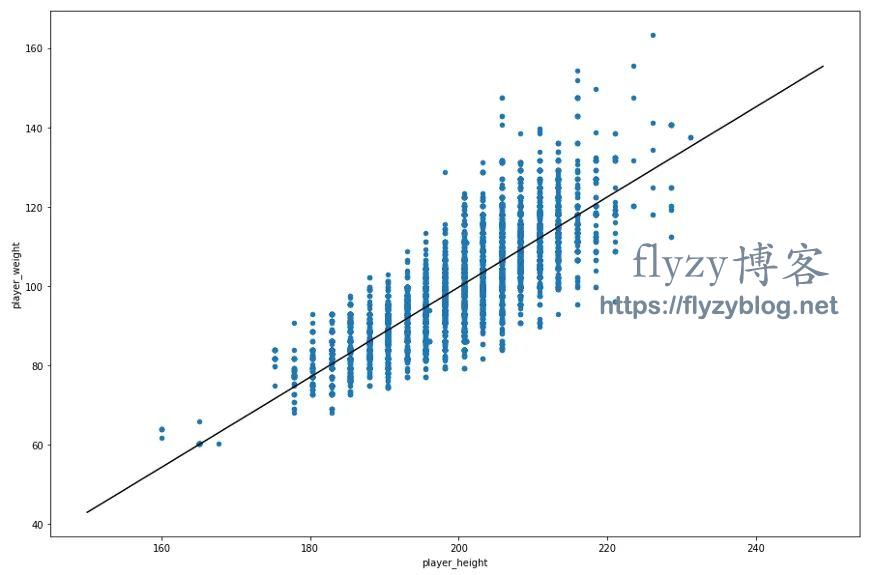
NBA 球员身高(X 轴)与体重(Y 轴)的散点图,这一次包括我们的线性回归模型创建的最佳拟合线。
在这种情况下,黑线是我们已经对数据拟合的直线。根据这条直线,我们可以推测,一个身高 180 厘米的球员大约在 70 公斤左右。但是,使用 SKLearn 和我们创建的模型,我们可以估算出:
model.predict(np.array(180).reshape(-1,1))
[3]: array([[77.00324856]])
因此,身高 180 厘米的球员应该大约有 77 公斤重。
现在这个模型已训练好,你可以用任何值进行尝试。下面是我在 NBA 的体重:
model.predict(np.array(188).reshape(-1,1))
[4]: array([[86.08788817]])
虽然这只是一个微不足道的例子,但线性回归对于许多任务和项目都非常有用,因此,每个人都应该尽可能掌握线性回归。我这个项目的完整代码如下所示,我鼓励你自己尝试一下。另外,如果你还想了解更多有关信息,我在下面提供了一些参考资料。
import pandas as pd
from sklearn import linear_model
df = pd.read_csv("archive/all_seasons.csv")
X = df["player_height"].to_numpy().reshape(-1, 1)
y = df["player_weight"].to_numpy().reshape(-1, 1)
lm = linear_model.LinearRegression()
model = lm.fit(X,y)
model.predict(np.array(188).reshape(-1,1))
哇!只需 8 行代码!!
Braden Riggs,澳大利亚人,加利福尼亚大学圣地亚哥分校数据科学系留学生,GSI Technology 实习生。
原文链接:
https://towardsdatascience.com/a-guide-to-building-your-first-regression-model-in-just-8-lines-of-code-2d1a2a755811






