


压测的一般流程和方法是什么?需要关注哪些数据指标?如何推算后端需要支持的qps?本文分享总结压测过程中需要注意的问题,希望对同学们有所启发,欢迎讨论。


- 后端
- 单api
- 单业务逻辑场景
- 前端
- 单request
- 单操作
- 单页
- 整体页面平均情况
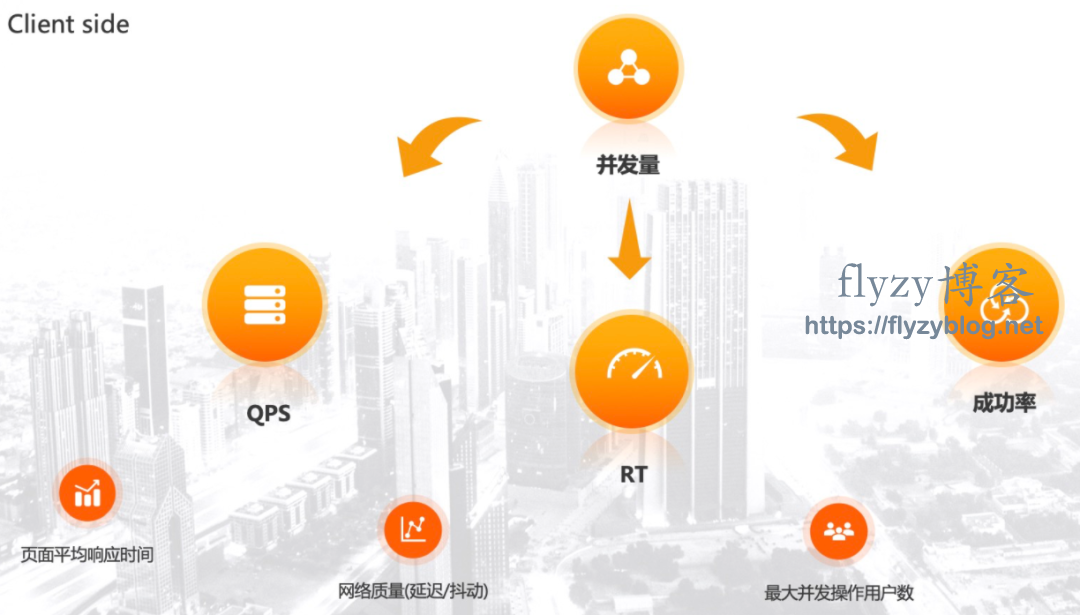
- qps
- rt
- 成功率
- 页面平均响应时间 (重要)。
- 并发量(其实没那么重要,主要还是qps)。
- 最大用户同时在线数 (用户登录系统,一般不需要额外压测,除非业务场景特殊)。
- 网络质量(延迟,波动等,不展开)。

- cpu usage
- load
- mem
- jvm/fullGC
- 连接数(netstat)
- disk io (iostat / iotop)
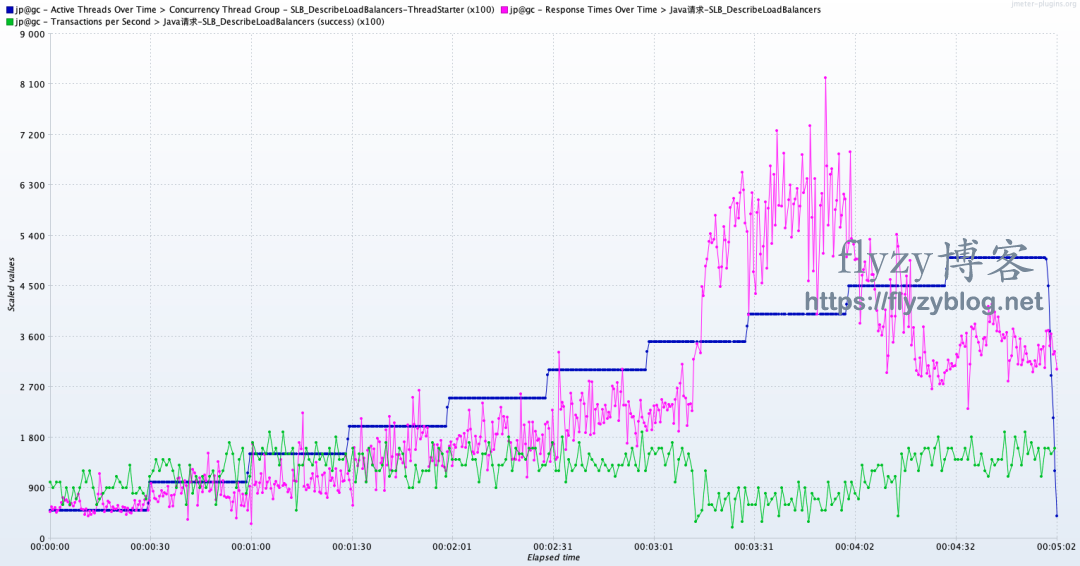
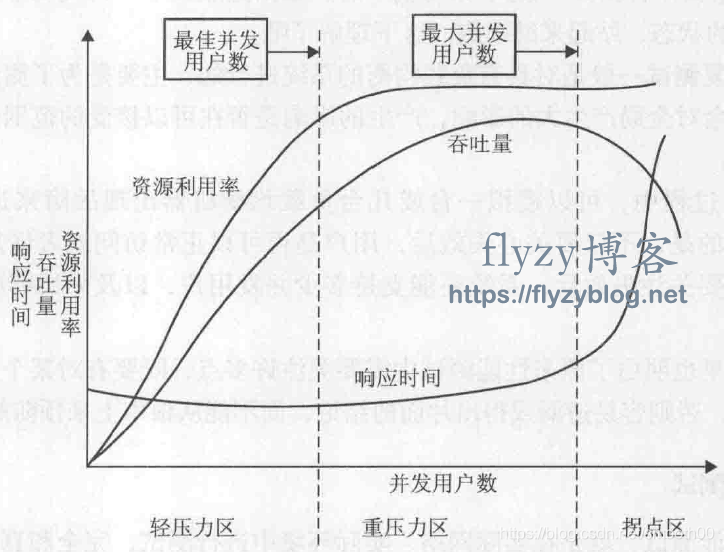
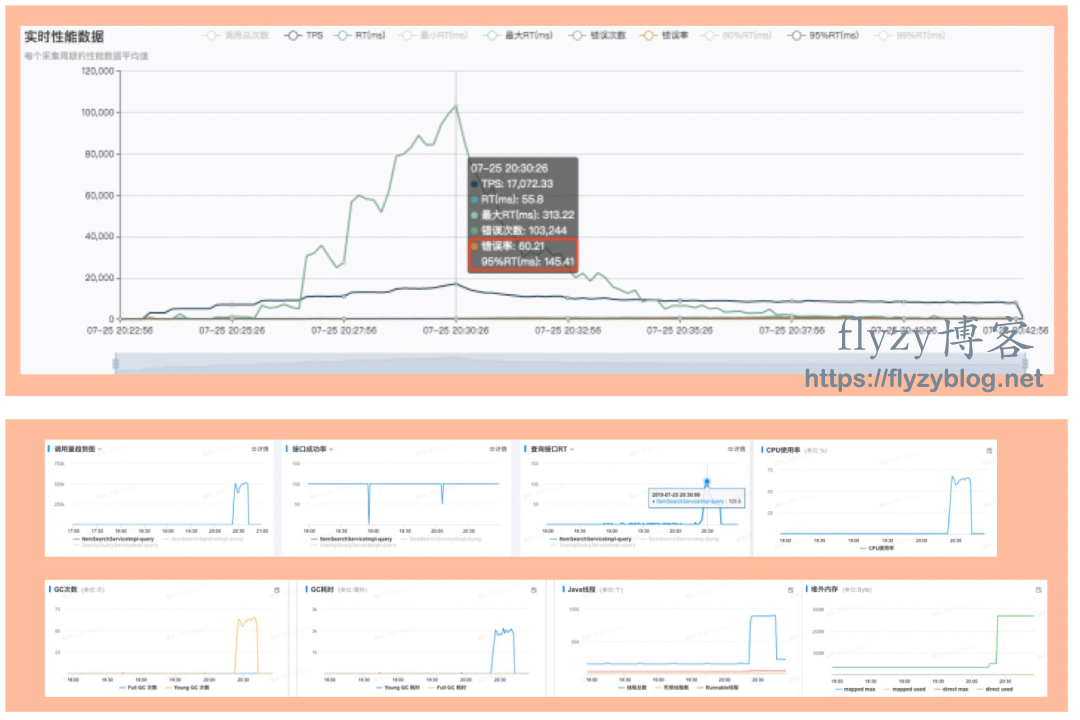
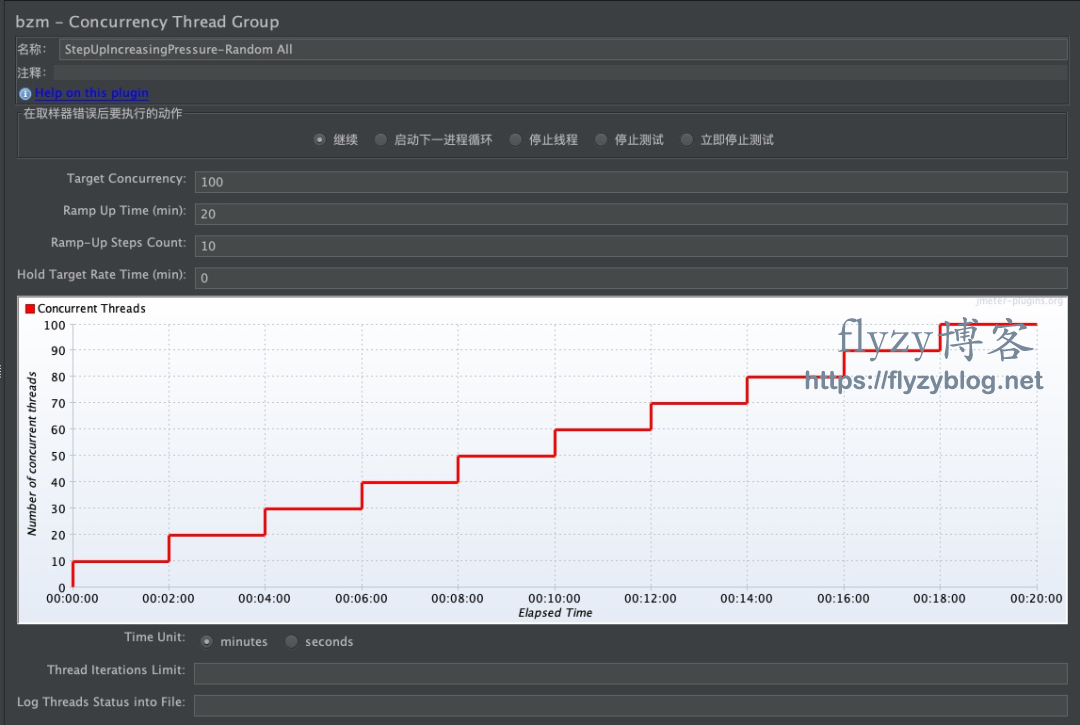

- 如果你提供的是一个在线的网页服务,那用户可能关心的是,你的系统在保证不察觉卡顿的情况下(系统的SLA, 实际可能容忍存在偶发的页面错误重试)能承受多少人并发使用。
- 如果你提供的是个结算系统,那用户可能关心的是,在保证交易有效性的情况下(不能出错,但是可以偶发超时重试,同样是系统的SLA),每秒可以处理多少笔订单。
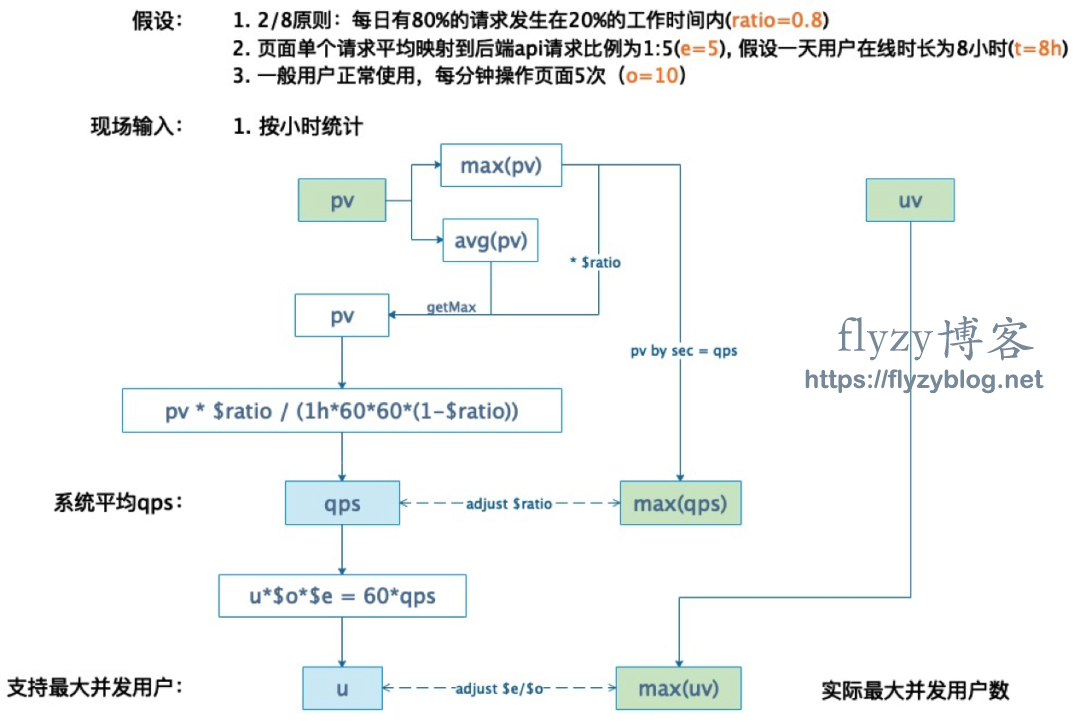
1. 获取现场每日asapi PV/UV的均值/峰值。
2. 取Max(PV峰值*0.8,每日PV均值)作为目标PV’, PV’时段的UV值作为实际并发用户参考值N’, 计算PV’/perMinute/N’作为每分钟用户操作触发api次数O’。
3. 根据以下规则换算成后端需要支持的qps:
- 3.1 模型假设:2/8原则——每日有80%的PV发生在20%的工作时间内(ratio=0.8)。
- 3.2 假设页面单个请求映射到后端api请求比例为1:10,假设一天working hour为8小时 (e=10)。
- 3.3 假设一般用户,高峰期每分钟操作页面10次 (o=10)。
- 3.4 根据现场日PV计算支持N’用户并发操作需要的qps:PV’ * ratio/(working hour∗60∗60∗(1−ratio) )= qps
- 3.5 根据现场峰值小时级PV计算支持N’用户并发操作需要的qps:PV’ * ratio/(1∗60∗60∗(1−ratio) ) = qps
4. 根据压测qps推算能够支持的最大用户同时使用数:
- 4.1 同样基于上述公式,根据上述假设,1分钟内,每个用户操作10次,每次前端操作对应后端10个api:
- 1分钟PV = N * 10 *10
- N *10 *10 / 60 = qps ==> N = qps * 0.6
- 4.2 如果按照小时为单位推算,1个小时内,每个用户操作页面100次,每次前端操作对应后端10个api:
- 60分钟PV = N * 100 *10
- N *100 *10 / 60*60 = qps ==> N = qps * 3.6
- 链路跟踪能力,分析瓶颈点
- api log
- eagleye-traceId
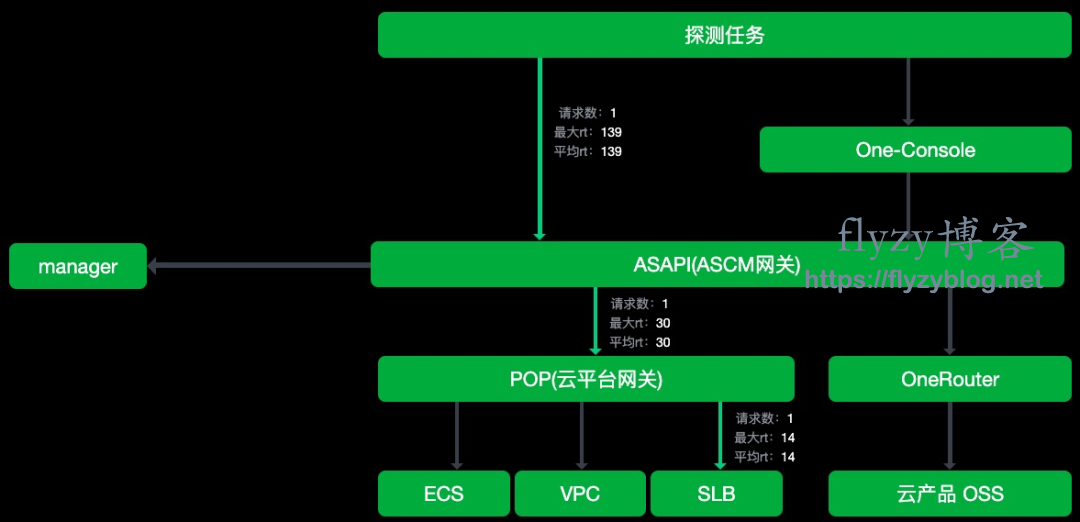
- 缓存对数据库的影响
- 是否需要压到db层,要考虑压测场景。
- 是否需要创造海量的随机压测数据 (比如针对单用户的缓存优化场景,单一用户的性能不能用来推送多用户并发的场景)。
- 同步接口异步接口的压测 (staragent)
- 主要考验后台任务处理能力(异步任务提交即时返回了)。
- 系统不同层次的限流设置对API的影响
- 比如有业务层的限流如Sentinel, Nginx层的限流如X5, 或者其他基于LVS的限流等。
- 消息通信,尤其是广播消息。
- 数据库,尤其是写一致性。
- 复杂场景的长链路调用。
- Nginx/Tomcat的配置对请求的影响。
- 容易忽视的对象序列化/反序列化对性能的影响。
- 热点数据。






