

本文目录

一 Calcite 中的访问者模式
import org.apache.calcite.sql.SqlCall;import org.apache.calcite.sql.SqlFunction;import org.apache.calcite.sql.SqlNode;import org.apache.calcite.sql.parser.SqlParseException;import org.apache.calcite.sql.parser.SqlParser;import org.apache.calcite.sql.util.SqlBasicVisitor;import java.util.ArrayList;import java.util.List;public class CalciteTest {public static void main(String[] args) throws SqlParseException {String sql = "select concat('test-', upper(name)) from test limit 3";SqlParser parser = SqlParser.create(sql);SqlNode stmt = parser.parseStmt();FunctionExtractor functionExtractor = new FunctionExtractor();stmt.accept(functionExtractor);// [CONCAT, UPPER]System.out.println(functionExtractor.getFunctions());}private static class FunctionExtractor extends SqlBasicVisitor {private final ListString> functions = new ArrayList();public Void visit(SqlCall call) {if (call.getOperator() instanceof SqlFunction) {functions.add(call.getOperator().getName());}return super.visit(call);}public ListString> getFunctions() {return functions;}}}
二 动手实现访问者模式
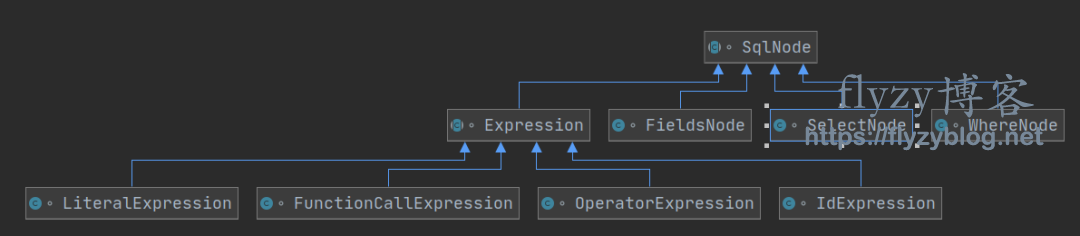
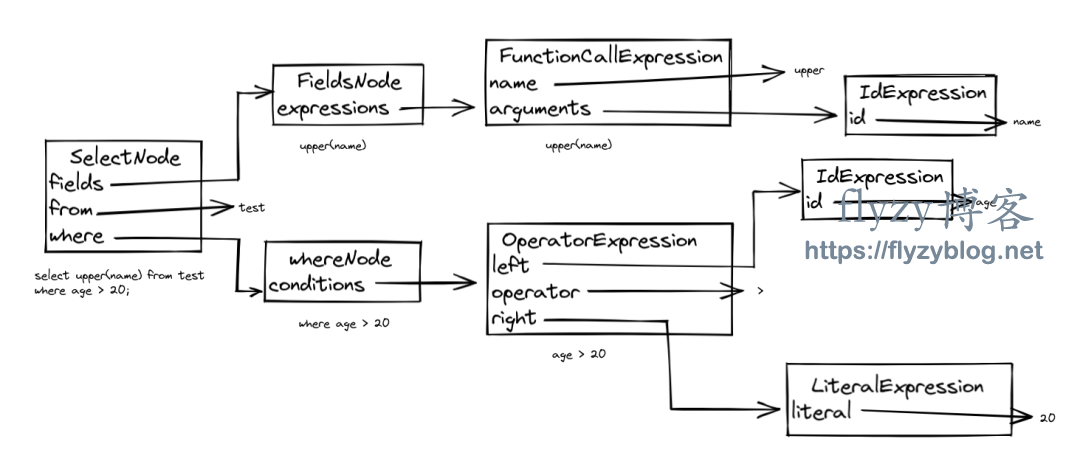
SqlNode sql = new SelectNode(new FieldsNode(Arrays.asList(new FunctionCallExpression("upper", Arrays.asList(new IdExpression("name"))))),Arrays.asList("test"),new WhereNode(Arrays.asList(new OperatorExpression(new IdExpression("age"),">",new LiteralExpression("20")))));
public R accept(SqlVisitor sqlVisitor) {return sqlVisitor.visit(this);}
abstract class SqlVisitorR> {abstract R visit(SelectNode selectNode);abstract R visit(FieldsNode fieldsNode);abstract R visit(WhereNode whereNode);abstract R visit(IdExpression idExpression);abstract R visit(FunctionCallExpression functionCallExpression);abstract R visit(OperatorExpression operatorExpression);abstract R visit(LiteralExpression literalExpression);}
abstract class SqlNode {// 用来接收访问者的方法public abstract R accept(SqlVisitor sqlVisitor);}class SelectNode extends SqlNode {private final FieldsNode fields;private final List from;private final WhereNode where;SelectNode(FieldsNode fields, List from, WhereNode where) {this.fields = fields;this.from = from;this.where = where;}public R accept(SqlVisitor sqlVisitor) {return sqlVisitor.visit(this);}//... get 方法省略}class FieldsNode extends SqlNode {private final List fields;FieldsNode(List fields) {this.fields = fields;}public R accept(SqlVisitor sqlVisitor) {return sqlVisitor.visit(this);}}class WhereNode extends SqlNode {private final List conditions;WhereNode(List conditions) {this.conditions = conditions;}public R accept(SqlVisitor sqlVisitor) {return sqlVisitor.visit(this);}}abstract class Expression extends SqlNode {}class IdExpression extends Expression {private final String id;protected IdExpression(String id) {this.id = id;}public R accept(SqlVisitor sqlVisitor) {return sqlVisitor.visit(this);}}class FunctionCallExpression extends Expression {private final String name;private final List arguments;FunctionCallExpression(String name, List arguments) {this.name = name;this.arguments = arguments;}public R accept(SqlVisitor sqlVisitor) {return sqlVisitor.visit(this);}}class LiteralExpression extends Expression {private final String literal;LiteralExpression(String literal) {this.literal = literal;}public R accept(SqlVisitor sqlVisitor) {return sqlVisitor.visit(this);}}class OperatorExpression extends Expression {private final Expression left;private final String operator;private final Expression right;OperatorExpression(Expression left, String operator, Expression right) {this.left = left;this.operator = operator;this.right = right;}public R accept(SqlVisitor sqlVisitor) {return sqlVisitor.visit(this);}}
class FunctionExtractor extends SqlVisitorString>> {ListString> visit(SelectNode selectNode) {ListString> res = new ArrayList();res.addAll(selectNode.getFields().accept(this));res.addAll(selectNode.getWhere().accept(this));return res;}ListString> visit(FieldsNode fieldsNode) {ListString> res = new ArrayList();for (Expression field : fieldsNode.getFields()) {res.addAll(field.accept(this));}return res;}ListString> visit(WhereNode whereNode) {ListString> res = new ArrayList();for (Expression condition : whereNode.getConditions()) {res.addAll(condition.accept(this));}return res;}ListString> visit(IdExpression idExpression) {return Collections.emptyList();}ListString> visit(FunctionCallExpression functionCallExpression) {// 获得函数名称ListString> res = new ArrayList();res.add(functionCallExpression.getName());for (Expression argument : functionCallExpression.getArguments()) {res.addAll(argument.accept(this));}return res;}ListString> visit(OperatorExpression operatorExpression) {ListString> res = new ArrayList();res.addAll(operatorExpression.getLeft().accept(this));res.addAll(operatorExpression.getRight().accept(this));return res;}ListString> visit(LiteralExpression literalExpression) {return Collections.emptyList();}}
public static void main(String[] args) {// sql 定义SqlNode sql = new SelectNode( //select// concat("test-", upper(name))new FieldsNode(Arrays.asList(new FunctionCallExpression("concat", Arrays.asList(new LiteralExpression("test-"),new FunctionCallExpression("upper",Arrays.asList(new IdExpression("name"))))))),// from testArrays.asList("test"),// where age > 20new WhereNode(Arrays.asList(new OperatorExpression(new IdExpression("age"),">",new LiteralExpression("20")))));// 使用 FunctionExtractorFunctionExtractor functionExtractor = new FunctionExtractor();ListString> functions = sql.accept(functionExtractor);// [concat, upper]System.out.println(functions);}
三 访问者模式与观察者模式
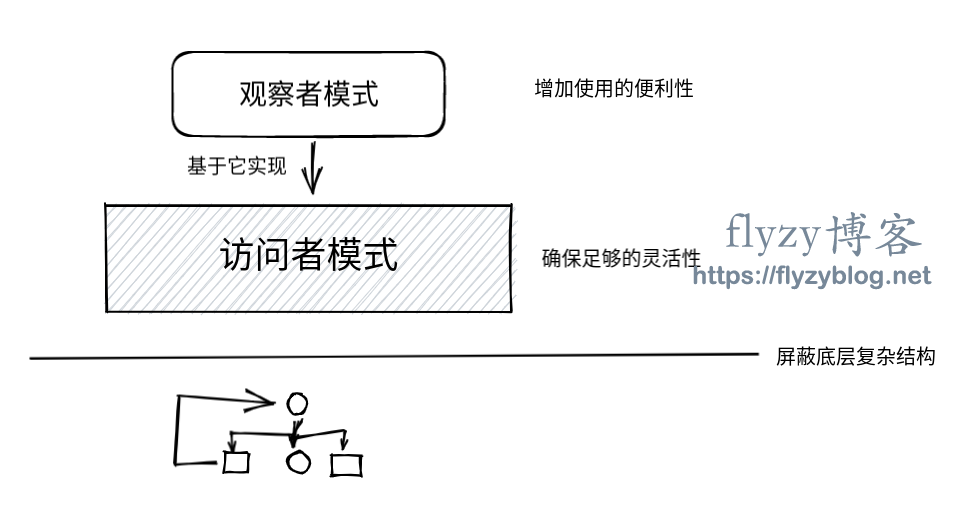
class SqlBasicVisitorR> extends SqlVisitorR> {R visit(SelectNode selectNode) {selectNode.getFields().accept(this);selectNode.getWhere().accept(this);return null;}R visit(FieldsNode fieldsNode) {for (Expression field : fieldsNode.getFields()) {field.accept(this);}return null;}R visit(WhereNode whereNode) {for (Expression condition : whereNode.getConditions()) {condition.accept(this);}return null;}R visit(IdExpression idExpression) {return null;}R visit(FunctionCallExpression functionCallExpression) {for (Expression argument : functionCallExpression.getArguments()) {argument.accept(this);}return null;}R visit(OperatorExpression operatorExpression) {operatorExpression.getLeft().accept(this);operatorExpression.getRight().accept(this);return null;}R visit(LiteralExpression literalExpression) {return null;}}
class FunctionExtractor2 extends SqlBasicVisitor {private final ListString> functions = new ArrayList();Void visit(FunctionCallExpression functionCallExpression) {functions.add(functionCallExpression.getName());return super.visit(functionCallExpression);}public ListString> getFunctions() {return functions;}}
class Main {public static void main(String[] args) {SqlNode sql = new SelectNode(new FieldsNode(Arrays.asList(new FunctionCallExpression("concat", Arrays.asList(new LiteralExpression("test-"),new FunctionCallExpression("upper",Arrays.asList(new IdExpression("name"))))))),Arrays.asList("test"),new WhereNode(Arrays.asList(new OperatorExpression(new IdExpression("age"),">",new LiteralExpression("20")))));FunctionExtractor2 functionExtractor = new FunctionExtractor2();sql.accept(functionExtractor);System.out.println(functionExtractor.getFunctions());}}
四 访问者模式与责任链模式
-
删除 name 属性 -
给所有属性添加 @NonNull 注解
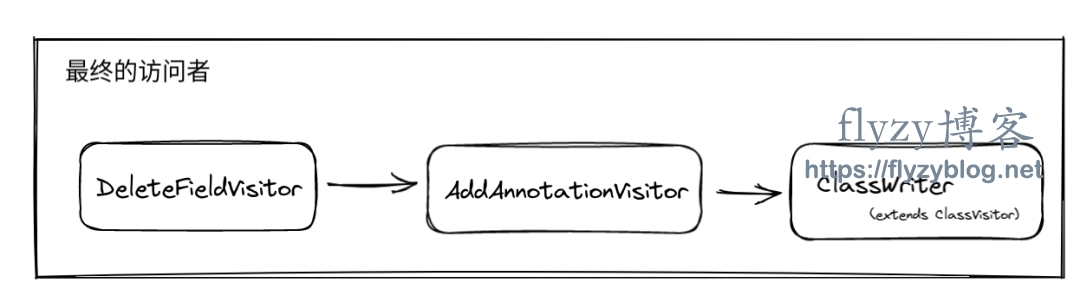
class DeleteFieldVisitor extends ClassVisitor {// 删除的属性名称, 对于我们的需求,它就是 "name"private final String deleteFieldName;public DeleteFieldVisitor(ClassVisitor classVisitor, String deleteFieldName) {super(Opcodes.ASM9, classVisitor);this.deleteFieldName = deleteFieldName;}public FieldVisitor visitField(int access, String name, String descriptor, String signature, Object value) {if (name.equals(deleteFieldName)) {// 不再向下游传递该属性, 对于下游来说,就是被 "删除了"return null;}// super.visitField 会去继续调用下游 Visitor 的 visitField 方法return super.visitField(access, name, descriptor, signature, value);}}
class AddAnnotationVisitor extends ClassVisitor {public AddAnnotationVisitor(ClassVisitor classVisitor) {super(Opcodes.ASM9, classVisitor);}public FieldVisitor visitField(int access, String name, String descriptor, String signature, Object value) {FieldVisitor fieldVisitor = super.visitField(access, name, descriptor, signature, value);// 向下游 Visitor 额外传递一个 @NonNull 注解fieldVisitor.visitAnnotation("javax/annotation/Nonnull", false);return fieldVisitor;}}
public class AsmTest {public static void main(String[] args) throws URISyntaxException, IOException {Path clsPath = Paths.get(AsmTest.class.getResource("/visitordp/User.class").toURI());byte[] clsBytes = Files.readAllBytes(clsPath);// 串联 Visitor// finalVisitor = DeleteFieldVisitor -> AddAnnotationVisitor -> ClassWriter// ClassWriter 本身也是 ClassVisitor 的子类ClassWriter cw = new ClassWriter(ClassWriter.COMPUTE_FRAMES);ClassVisitor finalVisitor = new DeleteFieldVisitor(new AddAnnotationVisitor(cw),"name");// ClassReader 就是被访问的对象ClassReader cr = new ClassReader(clsBytes);cr.accept(finalVisitor, ClassReader.SKIP_DEBUG | ClassReader.SKIP_FRAMES);byte[] bytes = cw.toByteArray();Files.write(clsPath, bytes);}}
五 访问者模式与回调模式
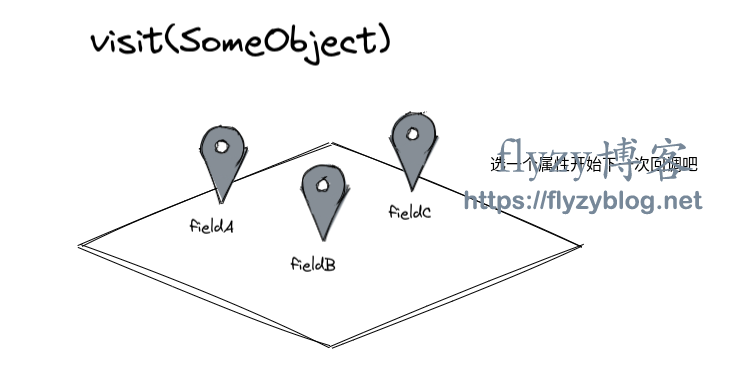
visit(SomeObject someObject) {someObject.fieldA.accept(this);someObject.fieldB.accept(this);someObject.fieldC.accept(this);}
----请求----GET /sittingroomHOST home.example.comAccept: application/xml----服务端返回----HTTP/1.1 200 OKContent-Type: application/xmlsittingroom>television>海康television>sofa>宜家sofa>link rel="kitchen" href="https://home.example.com/sittingroom/kitchen"/>link rel="bedroom" href="https://home.example.com/sittingroom/bedroom"/>link rel="toilet" href="https://home.example.com/sittingroom/toilet"/>sittingroom>
六 实际应用
1 复杂的嵌套结构访问
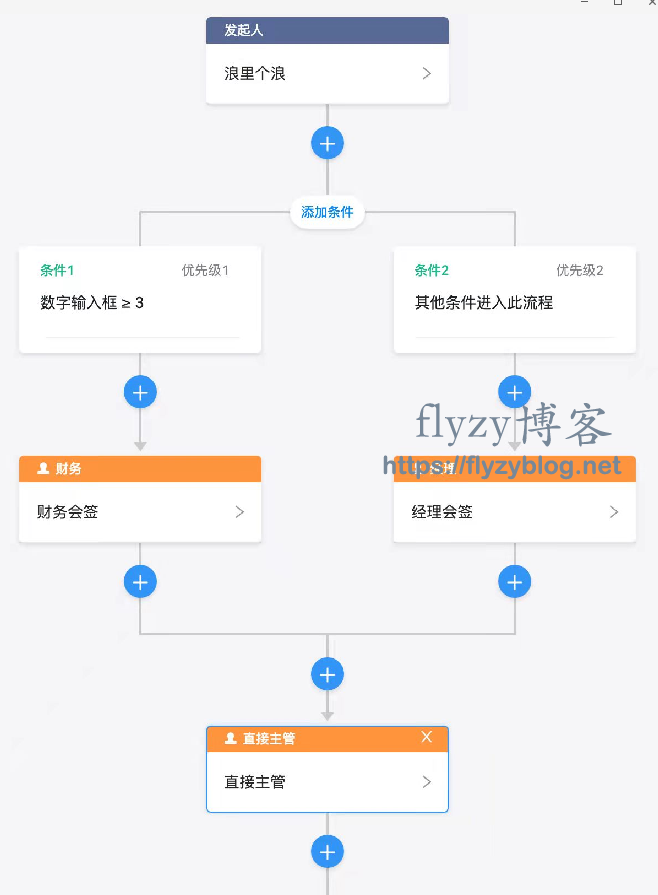
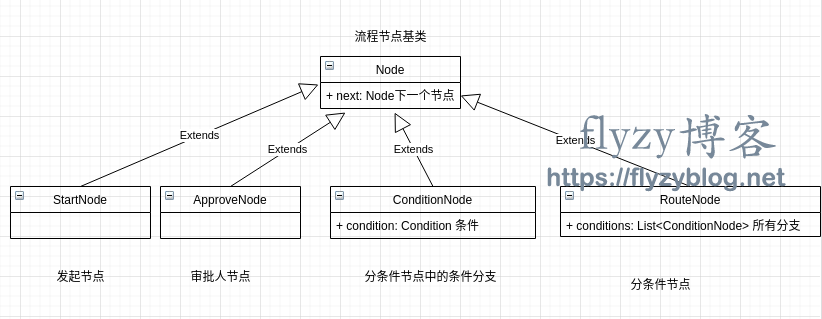
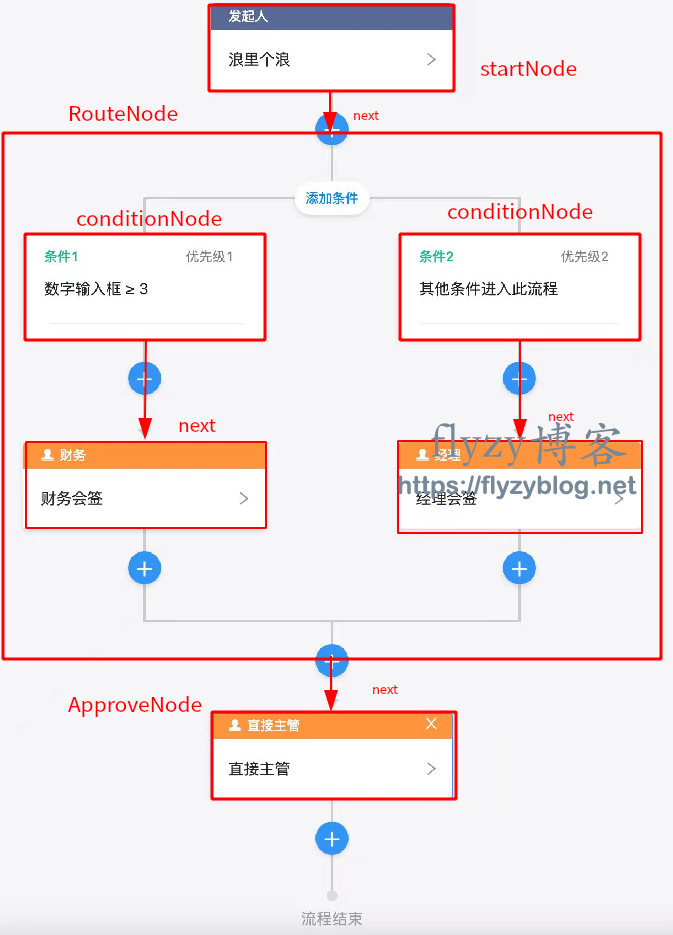
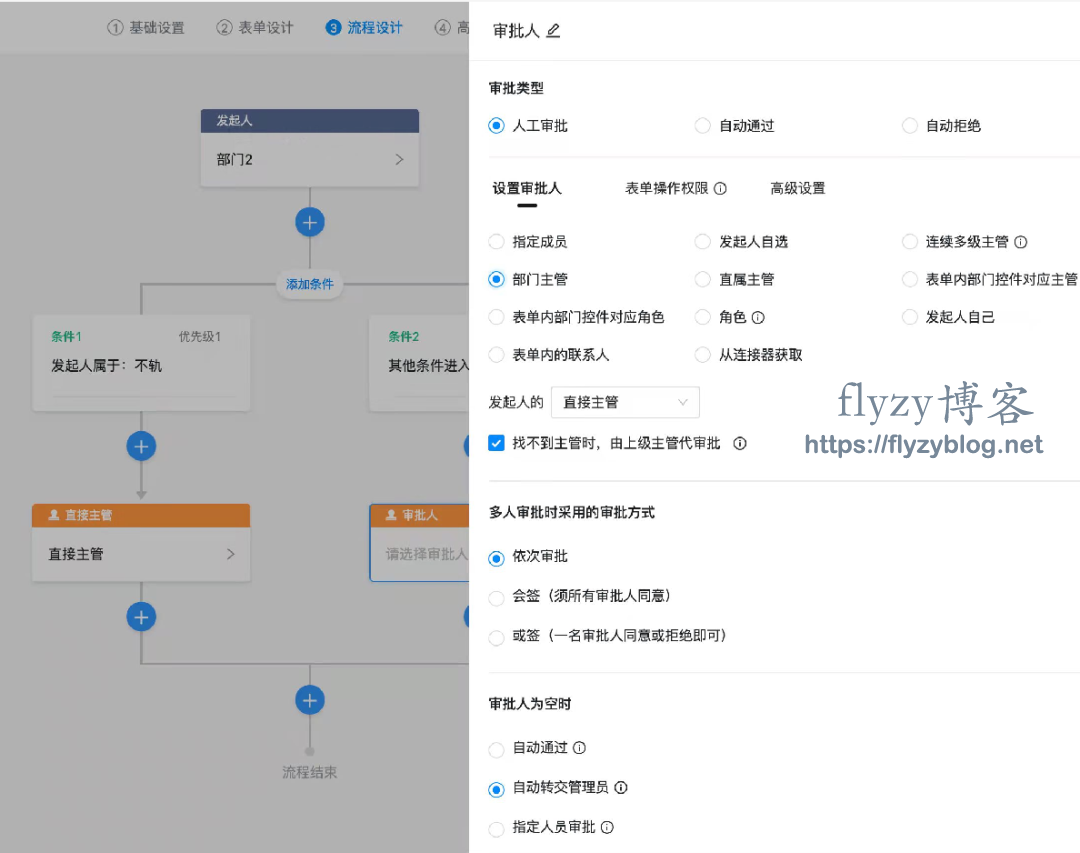
-
流程仿真:让用户在不实际运行流程的情况下就能看到流程的执行分支,方便调试
class ProcessSimulator implements ProcessConfigVisitor {private List traces = new ArrayList();public void visit(StartNode startNode) {if (startNode.next != null) {startNode.next.accept(this);}}public void visit(RouteNode routeNode) {// 计算出满足条件的分支for (CondtionNode conditionNode : routeNode.conditions) {if (evalCondition(conditionNode.condition)) {conditionNode.accept(this);}}if (routeNode.next != null) {routeNode.next.accept(this);}}public void visit(ConditionNode conditionNode) {if (conditionNode.next != null) {conditionNode.next.accept(this);}}public void visit(ApproveNode approveNode) {// 记录下在仿真中访问到的审批节点traces.add(approveNode.id);if (approveNode.next != null) {approveNode.next.accept(this);}}}
2 SDK 隔离外部调用
七 使用 Java18 实现访问者模式
// sealed 表示胶囊类型, 即 Expression 只允许是当前文件中 Num 和 Addsealed interface Expression {// record 关键字代替 class, 用于定义 Record 数据类型record Num(int value) implements Expression {}record Add(int left, int right) implements Expression {}}
public static void main(String[] args) {Num n1 = new Num(2);// n1.value = 10; 这行代码会导致编译不过Num n2 = new Num(2);// trueSystem.out.println(n1.equals(n2));}
public int eval(Expression e) {return switch (e) {case Num(int value) -> value;case Add(int left, int right) -> left + right;};}
sealed interface SqlNode {record SelectNode(FieldsNode fields, ListString> from, WhereNode where) implements SqlNode {}record FieldsNode(List fields) implements SqlNode {}record WhereNode(List conditions) implements SqlNode {}sealed interface Expression extends SqlNode {record IdExpression(String id) implements Expression {}record FunctionCallExpression(String name, Listarguments) implements Expression {}record LiteralExpression(String literal) implements Expression {}record OperatorExpression(Expression left, String operator, Expression right) implements Expression {}}}
public ListString> extractFunctions(SqlNode sqlNode) {return switch (sqlNode) {case SelectNode(FieldsNode fields, ListString> from, WhereNode where) -> {ListString> res = new ArrayList();res.addAll(extractFunctions(fields));res.addAll(extractFunctions(where));return res;}case FieldsNode(List fields) -> {ListString> res = new ArrayList();for (Expression field : fields) {res.addAll(extractFunctions(field));}return res;}case WhereNode(List conditions) -> {ListString> res = new ArrayList();for (Expression condition : conditions) {res.addAll(extractFunctions(condition));}return res;}case IdExpression(String id) -> Collections.emptyList();case FunctionCallExpression(String name, Listarguments) -> {// 获得函数名称ListString> res = new ArrayList();res.add(name);for (Expression argument : arguments) {res.addAll(extractFunctions(argument));}return res;}case LiteralExpression(String literal) -> Collections.emptyList();case OperatorExpression(Expression left, String operator, Expression right) -> {ListString> res = new ArrayList();res.addAll(extractFunctions(left));res.addAll(extractFunctions(right));return res;}}}
八 重新认识访问者模式
表示一个作用于某对象结构中的各元素的操作。它使你可以在不改变各元素的类的前提下定义作用于这些元素的新操作。
class SelectNode extends SqlNode {private final FieldsNode fields;private final Listfrom;private final WhereNode where;SelectNode(FieldsNode fields, Listfrom, WhereNode where) {this.fields = fields;this.from = from;this.where = where;}public FieldsNode getFields() {return fields;}public ListgetFrom() {return from;}public WhereNode getWhere() {return where;}public ListextractFunctions() {List res = new ArrayList();// 继续调用子结构的 extractFunctionsres.addAll(fields.extractFunctions());res.addAll(selectNode.extractFunctions());return res;}}
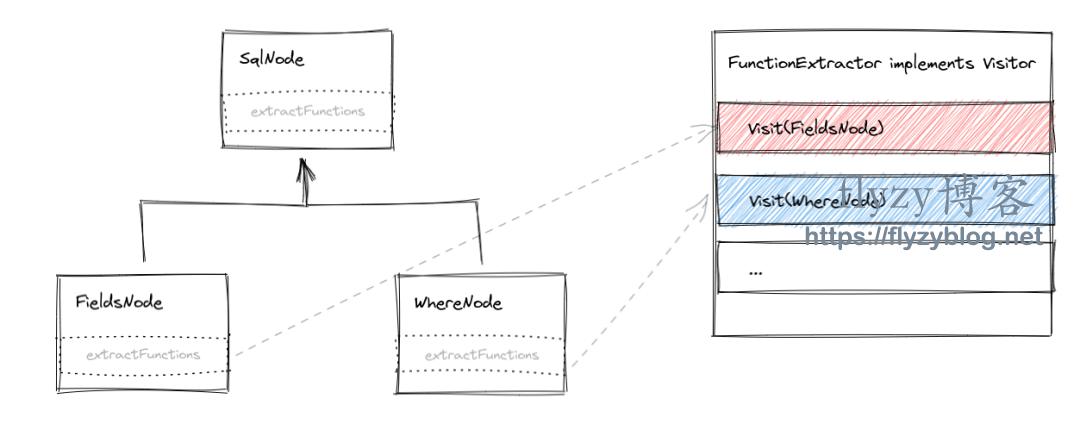
-
面向对象:认为操作必须和数据绑定到一起,即作为每个类的成员方法存在,而不是单独抽取出来成为一个访问者
-
函数式编程:将数据和操作分离,将基本操作进行排列组合成为更加复杂的操作,而一个访问者的实现就对应一个操作
-
成员函数实现方式:需要给类层级结构的每个类增加一个实现,需要修改原来的代码,不符合开闭原则
-
访问者实现方式:新建一个访问者即可,完全不影响原来的代码。占优。
-
成员函数实现方式:新建一个类即可,完全不影响原来代码。占优。
-
访问者实现方式:需要给每个访问者增加新类的代码实现,需要修改原来的代码,不符合开闭原则。
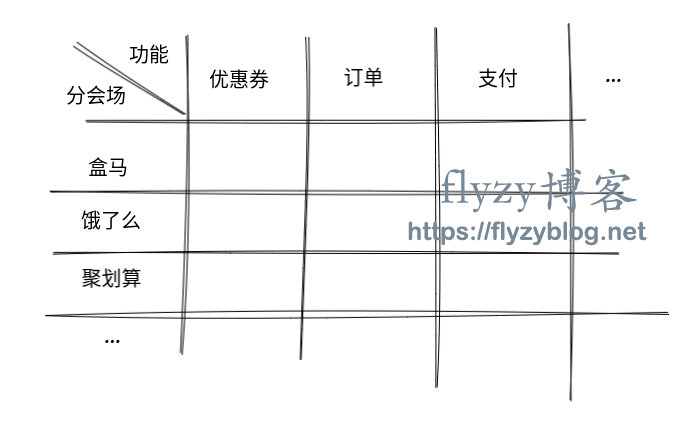
-
按应用划分:盒马,饿了么,聚划算这个三个系统完全独立,分别实现一遍三个功能点。虽然有重复造轮子的嫌疑,但是能够短平快地支撑创新业务,这可能就是所谓的“拆中台”。
-
按功能划分:将系统分为 优惠券系统,订单系统和支付系统,然后三个应用都使用相同的功能系统,在功能系统内部通过配置或者拓展点的方式处理业务之间的不同。这其实就是所谓的 “中台”,虽然能最大程度上地重用已有技术成果,但是中台的种种限制也会遏制创新业务的发展。
招聘信息:
笔者现任职于钉钉智能办公应用,团队的审批系统是国内目前最大规模的工作流系统,其灵活的流程搭建和表单搭建能力服务了上百万中小企业。
我们春季实习生招聘正在火热进行中,岗位有服务端开发/前端开发,Base 地可以是杭州或者北京,如果你是 23 届相关专业的毕业生,欢迎投简历到 qinyuan.dqy@alibaba-inc.com,邮件标题为 “姓名-院校-技术方向-来自阿里技术”






