

本文目录
一直以来,卷积神经网络对人们来说都是一个黑箱,我们只知道它识别图片准确率很惊人,但是具体是怎么做到的,它究竟使用了什么特征来分辨图像,我们一无所知。无数的学者、研究人员都想弄清楚CNN内部运作的机制,甚至试图找到卷积神经网络和生物神经网络的联系。
2013年,纽约大学的Matthew Zeiler和Rob Fergus的论文Visualizing and Understanding Convolutional Neural Networks用可视化的方法揭示了CNN的每一层识别出了什么特征,也揭开了CNN内部的神秘面纱。之后,也有越来越多的学者使用各种方法将CNN的每一层的激活值、filters等等可视化,让我们从各个方面了解到CNN内部的秘密。今天这篇文章,将会带大家从多个角度看看CNN各层的功能。
一、CNN每一层都输出了什么玩意儿
这个是最直接了解CNN每一层的方法,给一张图片,经过每一个卷积层,图片到底变成了啥。
这里,我用Keras直接导入VGG19这个网络,然后我自己上传一张照片,让这个照片从VGG中走一遭,同时记录每一层的输出,然后把这个输出画出来。
先引入必要的包:
import keras
from keras.applications.vgg19 import VGG19
from keras.preprocessing import image
from keras.applications.vgg19 import preprocess_input
from keras.models import Model
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
现在引入把我男神的图片上传一下,用keras的图片处理工具把它处理成可以直接丢进网络的形式:
img_path = 'andrew.jpg'
img = image.load_img(img_path, target_size=(200, 300))
plt.imshow(img)
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
x.shape
我输入的图像:

然后,我们导入VGG模型,去掉FC层(就是把include_top设为FALSE),因为如果有FC层在的话,由于FC层神经元个数是固定的,所以网络的输入形状就有限制,就必须跟原来的网络的输入一模一样。但是卷积层不受输入形状的限制,因此我们只保留卷积层(和池化层)。
VGG19有19个CONV或FC层,但是如果我们打印出所有层的话,会包括POOL层,所以不止19个。这里我取第2~20层的输出,作为我们研究的对象:
base_model = VGG19(weights='imagenet',include_top=False)
# 获取各层的输出:
layer_outputs = [layer.output for layer in base_model.layers[2:20]]
# 获取各层的名称:
layer_names = []
for layer in base_model.layers[2:20]:
layer_names.append(layer.name)
print(layer_names)
注意,这里的输出还没有实际的值!只是一个壳子,当我们把图片输入到模型中之后,它才有值。
然后我们组装我们新的模型:输入图片,同时输出各层的激活值:
# 组装模型:
model = Model(inputs=base_model.input, outputs=layer_outputs)
# 将前面的图片数据x,输入到model中,得到各层的激活值activations:
activations = model.predict(x)
就这么easy!(如果不太明白代码的含义,可以参见Keras文档。)
这个activations里面,就装好了各层的所有的激活值。我们可以随便找一层的activation打印出来它的形状看看:
print(activations[0].shape)
#输出:
#(1, 200, 300, 64)
什么意思呢?
– 1,代表输入图片的个数,我们这里只输入了一个图片,所以是1;
– 200,300,代表图片的大小;
– 64,代表该层有多少个filters。
所以,相当于我们的这一层输出了64张单通道图片。
好了,我们可以将每一层激活得到的图片打印出来看看了。我们将每一层所有filters对应的图片拼在一起显示,代码如下:
import math
for activation,layer_name in zip(activations,layer_names):
h = activation.shape[1]
w = activation.shape[2]
num_channels = activation.shape[3]
cols = 16
rows = math.ceil(num_channels/cols)
img_grid = np.zeros((h*rows,w*cols))
for c in range(num_channels):
f_r = math.ceil((c+1)/cols)
f_c = (c+1)if f_r==1 else (c+1-(f_r-1)*cols)
img_grid[(f_r-1)*h:f_r*h,(f_c-1)*w:f_c*w ] = activation[0,:,:,c]
plt.figure(figsize=(25,25))
plt.imshow(img_grid, aspect='equal',cmap='viridis')
plt.grid(False)
plt.title(layer_name,fontsize=16)
plt.show()
这个代码感觉写的不大好。。。如果读者有更好的方法,也请麻烦告知。
最后是输出了18张大图,由于版面限制,我这里就挑其中的一些来展示:
①很靠前的一层:

可以看到,里面很多图片都跟我们的输入图片很像。如果我们放大仔细观察的话,比如:

可以发现,很多图片都是把原图片的 边缘勾勒了出来。因此,我们知道,该层主要的功能是边缘检测。
这里再说一下我们分析的思路:
根据前面讲解的CNN的原理,我们知道,当filter和我们的原图像的对应部分越像,它们卷积的结果就会越大,因此输出的像素点就越亮!因此,我们可以通过分析输出图片哪些部分比较亮来得知,该层的filters的作用。
所以,其实该层不光是“边缘检测”,还有一个功能——“颜色检测”。因为我还发现了很多这样的图片:

这些图中的 高亮部分,都对应于原图片中的整块的颜色,因此我们可以推断 该层的部分filters具有检测颜色的功能。
很有意思~
②中间的某一层:
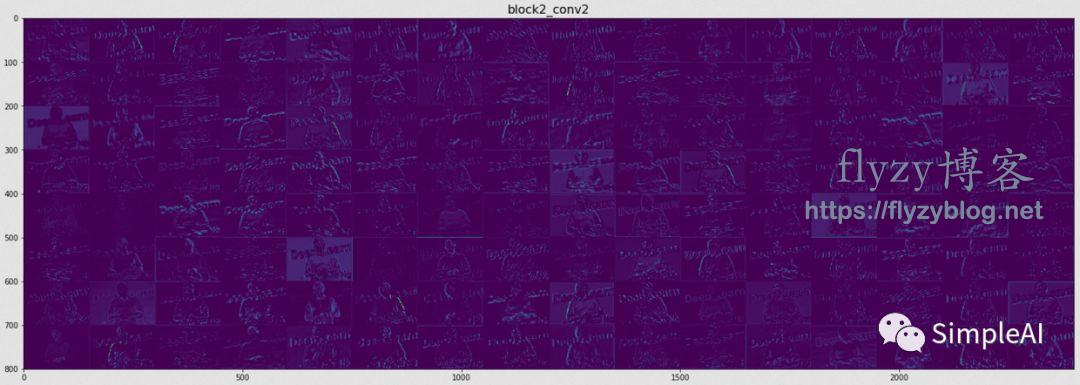
还是放大看一看:

这一层似乎复杂了很多,因为我们搞不清楚这些高亮的部分是一种什么特征,似乎是某种纹路。因此,和前面那个很浅的层相比,这一层提取的特征就没那么直白了。
③最后看一个很深的层:
(图太大,我截取部分)

这大概是VGG的第十几层吧,由于经过反复的卷积,图片大小会缩小,因此越来越“像素化”,这个时候,我们可以把这些激活图片,跟原图片去对比,看看原图片哪些部分被激活了:

从这个图可以看到,Andrew整个上半身都被激活了。
再看看这个:

Andrew的 手部被激活了。
更多的例子等大家自己去尝试。我们由此可以合理的推测,该层,已经可以将一些较复杂的东西作为特征来识别了,比如“手”、“身体”等等。这些特征比前面浅层的“边缘”、“颜色”等特征高级了不少。
为了让大家更全面地看到各层的状态, 我从每层中调了一张图片排在一起打印出来:

综上:随着CNN的层数增加,每一层的输出图像越来越抽象,这意味着我们的filters在变得越来越复杂;我们可以很合理地推断,随着CNN的深入,网络层学得的特征越来越高级和复杂。
二、CNN的每一层的filters到底长啥样
在上面,我们已经知道了每一层的输出是什么样子,并且由此推测每一层的filters越来越复杂。于是,我们就想进一步地探索一下,这些filters,到底在识别些什么,到底长啥样?
这里就有一个大问题:
比如VGG,我们前面讲过这是一个十分规则的网络,所有的filter大小都是3×3。这么小的玩意儿,画出来根本看不出任何猫腻。所有无法像我们上面画出每一层的激活值一样来分析。
那么怎么办呢?
我们依然可以用刚刚的思路来分析:
当输入图片与filter越像,他们的卷积输出就会越大。因此,给CNN喂入大量的图片,看看哪个的输出最大。但这样可行度不高,可以换个思路:我们可以直接输入一个噪音图片,用类似梯度下降的方法来不断更新这个图片,使得我们的输出结果不断增大,那么这个图片就一定程度上反映了filter的模样。
这里实际上不是用 梯度下降,而是用 梯度上升,因为我们要求的是一个极大值问题,而不是极小值问题。
梯度下降的更新参数w的过程,就是w→w-α·dw,其中α是学习率,dw是损失对w的梯度。梯度上升是类似的,是更新输入x,更新的方向变了:x→x+s·dx,其中s代表步长,与α类似,dx是激活值对x的梯度。
所以,我们可以仿照梯度下降法,来构造梯度上升算法。
具体方法和代码可以参见keras的发明者Fchollet亲自写的教程:
【https://nbviewer.jupyter.org/github/fchollet/deep-learning-with-python-notebooks/blob/master/5.4-visualizing-what-convnets-learn.ipynb】
这里我展示一下从浅到深的5个卷积层的filters的模样(注意,这个不是真的filters,而是输入图片,因为这个输入图片与filters的卷积结果最大化了,所以我们这里用输入图片的模样来代表filters的模样):
【预警:图片可能引起密恐者不适】
block1-conv3:

这一层,印证了我们之前的推断:这个很靠近输入的浅层的filters的功能,就是 “边缘检测”和“颜色检测”。
可能还是有同学不大明白,毕竟这个问题我也想了好久,为什么图片会这么密密麻麻的,看的让人瘆得慌?因为这个不是真的filter!filter大小只有3×3,而这些图片的大小都是我们设置的输入图片大小150×150,加入我们的某个filter是检测竖直边缘,那么输入图片要使卷积的结果最大,必然会到处各个角落都长满竖直的条条,所以我们看到的图片都是密密麻麻的某种图案的堆积。
block2-conv3:

block3-conv3:

block4-conv3:
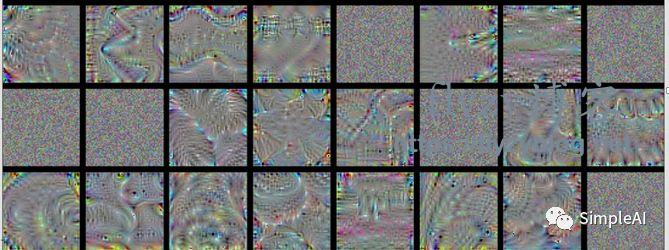
block5-conv3:
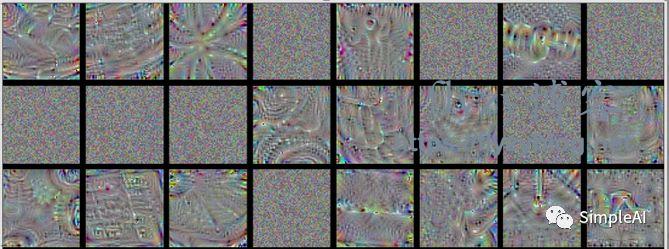
到了这个比较深的层,我们发现,图片的图案更加复杂了,似乎是 前面那些小图案组成的大图案,比如有类似 麻花的形状,有类似 蜘蛛网的形状,等等,我们直接说不出来,但是明显这些filters识别的特征更加高级了。
由于我只选取了部分的filters可视化,所以这里看不到更多的图案,也许把该层的几百个filters都打印出来,我们可以找到一些像虫子、手臂等东西的图案。
同时我们发现,越到深层,图片这种密密麻麻的程度就会降低,因为越到深层,filters对应于原图像的 视野就会越大,所以特征图案的范围也会越大,因此不会那么密集了。
另外,如果细心的话,我们可以注意到,越到深层,filters越稀疏,表现在图中就是像这种失效图片越来越多:

这些图片就是纯噪音,也就是根本没有激活出什么东西。具体原因我还不太清楚,等日后查清楚了再补充。但从另一个侧面我们可以理解:越深层,filters的数目往往越多,比如我们这里的block1-conv3,只有64个filters,但是最后一层block5-conv3有多达512个filters,所以有用的filters必然会更加稀疏一些。
综上:我们现在可以明白(刚刚是推断),CNN的浅层的filters一般会检测“边缘”、“颜色”等最初级的特征,之后,filters可以识别出各种“纹理纹路”,到深层的时候,filters可以检测出类似“麻花”、“蜘蛛”等等由前面的基础特征组成的图案。
三、更近一步,用Deconvnet可视化filters
在CNNs可视化中最有名的的论文当属我们文首提到的:
Matthew D. Zeiler and Rob Fergus:Visualizing and Understanding
Convolutional Networks.
无论是吴恩达上深度学习还是李飞飞讲计算机视觉,都会引用这个论文里面的例子,有空推荐大家都去看看这个论文。
我看了好久不太懂,但是写完上面的“第一部分”之后,我似乎理解了作者的思路。
我们回到我们在“一”中得到的某个深层的激活值:

然后,我试着把原图贴上去,看看它们哪些地方重合了:

当时,我们惊喜地发现,“上半身”、“手”、“Ng”被精准地激活了。
而上面那篇论文的作者,正是沿着 “将激活值与输入图片对应”这种思路(我的猜测),利用 Deconvnet这种结构,将激活值沿着CNN反向映射到输入空间,并重构输入图像,从而更加清晰明白地知道filters到底识别出了什么。可以说,这个思路,正式我们上面介绍的“一”、“二”的结合!
我画一个草图来说明:
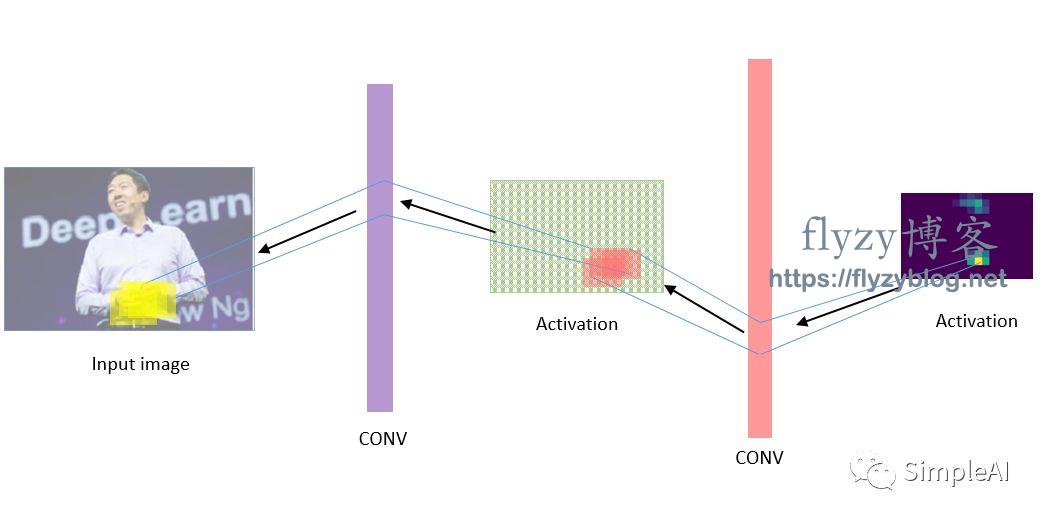
我这个草图相当地“草”,只是示意一下。
具体的方法,其实是将原来的CNN的顺序完全反过来,但是组件不变(即filters、POOL等等都不变),如 原来的顺序是:
input→Conv→relu→Pool→Activation
现在就变成了:
Activation→UnPool→relu→DeConv→input
这里的UNPool和DeConv,是对原来的Pool和conv的逆操作,这里面的细节请翻阅原论文,对于DeConv这个操作,我还推荐看这个:https://arxiv.org/abs/1603.07285
其实说白了,Conv基本上是把一个大图(input)通过filter变成了小图(activation),DeConv就反过来,从小图(activation)通过filter的转置再变回大图(input):
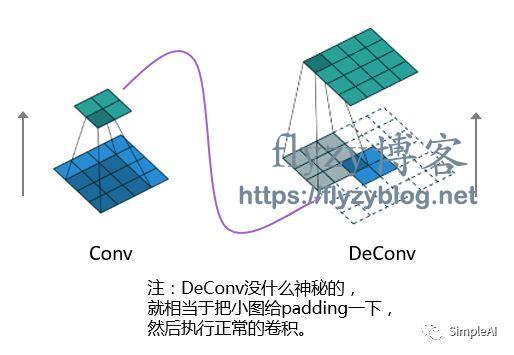
于是,我们把每一层的激活值中挑选最大的激活值,通过Deconvnet传回去,映射到输入空间重构输入图像。这里,我直接把论文中的结论搬出来给大家看看:

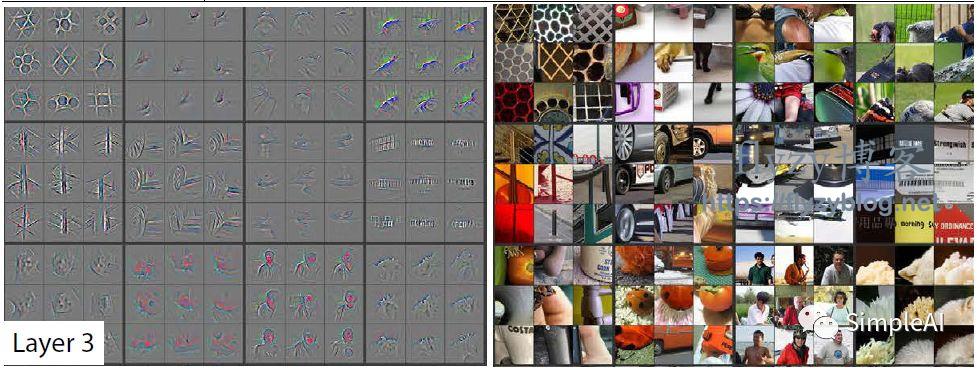

(左边这些灰色的图案就是我们激活值通过DeConvnet反向输出的,右边的是跟左边图案对应的原图案的区域)
我们可以看出,第一层,filters识别出了各种边缘和颜色,
第二层识别出了螺旋等各种纹路;
第三层开始识别出轮胎、人的上半身、一排字母等等;
第四层,已经开始识别出狗头、鸟腿;
第五层城市直接识别出自行车、各种狗类等等完整的物体了!
其实我们发现这个跟我们在“二”中得到的似乎很像,但是 这里得到的图案是很具体的,而“二”中得到的各层的图案很抽象。这是因为,在这里,我们不是讲所有的激活值都映射回去,而是挑选最突出的某个激活值来进行映射,而且,在“二”中,我们是从一个噪音图像来生成图案使得激活值最大(存在一个训练的过程),而这里是直接用某个具体图片的激活值传回去重构图片,因此是十分具体的。
综上面的所有之上
CNNs的各层并不是黑箱,每一层都有其特定个功能,分工明确。从浅到深,CNN会逐步提取出边缘、颜色、纹理、各种形状的图案,一直到提取出具体的物体。
也就是说,CNNs在训练的过程中,自动的提取了我们的任务所需要的各种特征:
这些特征,越在浅层,越是普遍和通用;
越在深层,就越接近我们的实际任务场景。
因此,我们可以利用以及训练好的CNNs来进行 迁移学习(transfer learning),也就是直接使用CNNs已经训练好的那些filters(特征提取器),来提取我们自己数据集的特征,然后就可以很容易地实现分类、预测等等目的。
参考资料:
-
Matthew D. Zeiler and Rob Fergus:Visualizing and Understanding
Convolutional Networks:https://arxiv.org/pdf/1311.2901v3.pdf -
A guide to convolution arithmetic for deep learning:https://arxiv.org/abs/1603.07285
-
https://nbviewer.jupyter.org/github/fchollet/deep-learning-with-python-notebooks/blob/master/5.4-visualizing-what-convnets-learn.ipynb






